Get In-Demand Finance Certifications
An algorithm that converts a message into a hash value

A hash function is a mathematical function or algorithm that simply takes a variable number of characters (called a ”message”) and converts it into a string with a fixed number of characters (called a hash value or simply, a hash).
The act of hashing is, therefore, running an input into a formula that converts it into an output message of fixed length. No matter how many characters long the input is, the output will always be the same in terms of the number of hexadecimal (letters and numbers) characters.
Hashing is useful to ensure the authenticity of a piece of data, as any small change to the message will result in a completely different hash value.
Hash functions are the basic tools of modern cryptography that are used in information security to authenticate transactions, messages, and digital signatures.
Hashing is generally a one-way function, which means that it is easy to convert a message into a hash but very difficult to “reverse hash” a hash value back to its original message as it requires a massive amount of computing power.
This difficulty is what cryptocurrencies like Bitcoin, which uses proof-of-work systems, depend on to ensure the integrity of their blockchain.
When you hash a message, it takes your file or message of any size, runs it through a mathematical algorithm, and spits out an output of a fixed length.
Table 1: Different Hash Functions

In Table 1 above, I have converted the same input message (the letters CFI) into hash values using three different hash functions (MD5, SHA-1, and SHA-256). Each one of those different hash functions will spit out an output hash that has a set fixed length of hexadecimal characters. In the case of MD5, it is 32 characters, SHA-1, 40 characters, and SHA-256, 64 characters.
Table 2: Different Inputs Using the Same Hash Function (SHA-1)
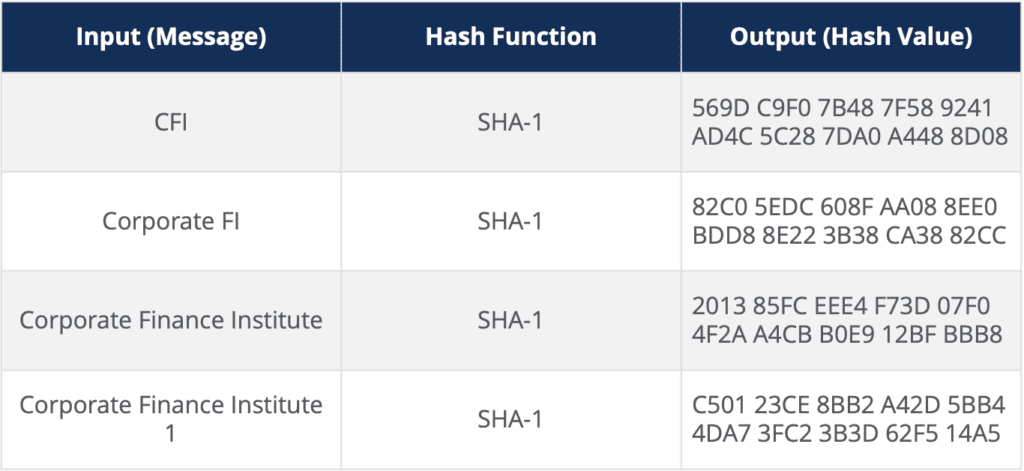
It doesn’t matter what we put in as an input, the same hash function will always produce a hash value that has the the same number of characters. In Table 2 above, we change the message each time, but using the same hash function (SHA-1 in this case), the output is always 40 hexadecimal characters long.
Let’s think of an example where you want to send a digital message or document to someone, and you want to make sure that it hasn’t been tampered with along the way. You could send it multiple times and have the recipient verify each copy is the same, but that would not be feasible if the file or message was very large.
It would be much easier if there was a way of having a shorter and set number of characters for the sender and receiver to check. And that’s essentially what a hash function allows two computers to do.
Rather than compare the data in its original (and larger) form, by comparing the two hashes of the data, computers can quickly confirm that the data has not been tampered with and changed.
Hash functions, therefore, serve as a check-sum or a way for someone to identify whether digital data has been tampered with after it’s been created.
For example, if you send out an email, it can be intercepted easily (especially if it is sent over an unsecured WiFi network). The recipient of the email has no way of knowing if someone has altered the contents of the email along the way, called a “Man-in-the-Middle” (MitM) attack.
However, if the sender signs the email with their digital signature and hashes that together with the email contents, the receiver can examine the hash data to ensure that the email contents have not been modified after being digitally signed.
To do this, the receiver would compare the hash value on the digitally-signed email received to a hash value they “re-generate” themselves using the same hash function provided by the sender, as well as the signer’s public key.
If it matches, that means that no one has altered the message, but if the hashes are different, then the receiver knows that the contents of the email are not authentic, as even if something small has been changed in that message, the hash will be completely different.
A hash function depends on the algorithm but generally, to get the hash value of a set length, it needs to first divide the input data into fixed-sized blocks, which are called data blocks.
This is because a hash function takes in data at a fixed length. The size of the data block is different from one algorithm to another.
If the blocks are not big enough, they may add padding to fill it out. However, regardless of what method of hashing you use, the output, or hash value, is always the same fixed length.
The hash function is then repeated as many times as the number of data blocks.
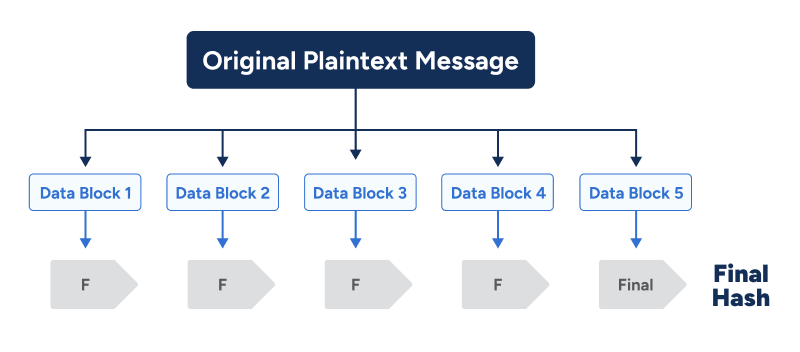
The data blocks are processed one at a time. The output of the first data block is fed as input along with the second data block. Consequently, the output of the second is fed along with the third block, and so on.
Thus, making the final output the combined value of all the blocks. If you change one bit anywhere in the message, the entire hash value changes. This is called ‘the avalanche effect.
Hash functions must be Deterministic – meaning that every time you put in the same input, it will always create the same output.
In other words, the output, or hash value, must be unique to the exact input. There should be no chance whatsoever that two different message inputs create the same output hash. If a hash function produces the same output from two different pieces of data, it is known as a “hash collision,” and the algorithm is useless.
Ideally, hash functions should be irreversible. Meaning that while it is quick and easy to compute the hash if you know the input message for any given hash function, it is very difficult to go through the process in reverse to compute the input message if you only know the hash value.
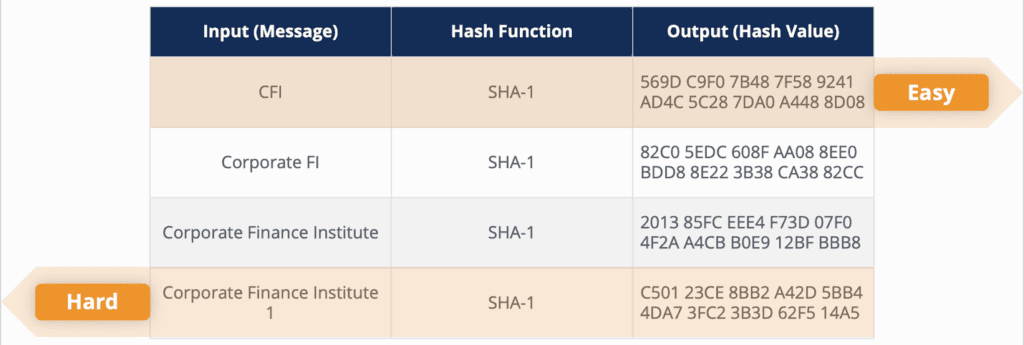
However, it is possible to compute the input given the output hash value, and that involves lots of computing power. Computing from right to left is called a “brute force” search, using trial and error to find a message that fits the hash value and see if it produces a match.
The most famous cryptocurrency, Bitcoin, uses hash functions in its blockchain. Powerful computers, called miners, race each other in brute force searches to try to solve hashes in order to earn the mining rewards of new Bitcoins, as well as processing fees that users pay to record their transactions on the blockchain.
Solving a hash involves computing a proof-of-work, called a NONCE, or “number used once”, that, when added to the block, causes the block’s hash to begin with a certain number of zeroes. Once a valid proof-of-work is discovered, the block is considered valid and can be added to the blockchain.
Since each block’s hash is created by a cryptographic algorithm – Bitcoin uses the SHA-256 algorithm – the only way to find a valid proof-of-work is to run guesses through the algorithm until the right number is found that creates a hash that starts with the right number of zeroes. This is what Bitcoin miners are doing, running numbers through a cryptographic algorithm until they guess the valid NONCE.
The SHA-256 function that Bitcoin uses is short for “Secure Hash Algorithm” and was designed by the United States National Security Agency (NSA) and includes SHA-1, SHA-2 (a family within a family that includes SHA-224, SHA-256, SHA-384, and SHA-512), and SHA-3 (SHA3-224, SHA3-256, SHA3-384, and SHA3-512).
Other examples of common hashing algorithms include:
Generally speaking, the most popular hashing algorithms or functions have a hash length ranging from 160 to 512 bits.
Any piece of digital information, like a file on your computer, a photo on your smartphone, or a block on a cryptocurrency blockchain, has a hash. And each hash is unique to each piece of data – any small change in the underlying information will lead to a completely different hash.
Apart from cryptocurrencies and other blockchain technologies, hash functions can be found throughout public key cryptography in everything from signing new software and verifying digital signatures to securing the website connections in your computer and mobile web browsers.
Encryption is the practice of taking data and creating a scrambled message in a way that only someone with a corresponding key, called a cipher, can unscramble and decode it. Encryption is a two-way function, designed to be reversible by anyone who holds a cipher. So when someone encrypts something, it is done with the intention of decrypting it later.
Hashing is using a formula that converts data of any size to a fixed length. The computing power required to “un-hash” something makes it very difficult so whereas encryption is a two-way function, hashing is generally a one-way function.
Encryption is meant to protect data in transit, hashing is meant to verify that a file or piece of data hasn’t been altered—that it is authentic. So you might liken encryption to putting a piece of data in a safe that opens when the recipient knows the combination; hashing is more like a security tamper seal that indicates if the contents of the data have been altered.
Thank you for reading CFI’s guide to Hash Functions. To keep learning and developing your knowledge base, please explore the additional relevant resources below: